一次 SQL 注入排查复盘:NestJS、日志与服务端安全
从一次小程序安全测试触发的 SQL 注入排查出发,复盘 NestJS 参数校验、ORM 查询写法、日志定位、数据库约束和服务端安全防线。
之前做过一个小程序,服务端用 NestJS,数据库是 MySQL。小程序提审时,微信平台提供了一次接口安全测试,模拟用户请求去探测常见漏洞。
测试本身没有造成真实破坏,但数据库里被写入了几十条不符合预期的空白记录。这个问题影响范围不大,却很适合复盘:它暴露的不是某一行 parseInt 忘了写,而是服务端安全里几层防线都不够完整。
English version: A SQL Injection Incident Review: NestJS Validation, Logs, and Server-Side Security
问题是怎么发现的
小程序提审时,微信后台提示可以进行接口安全测试:
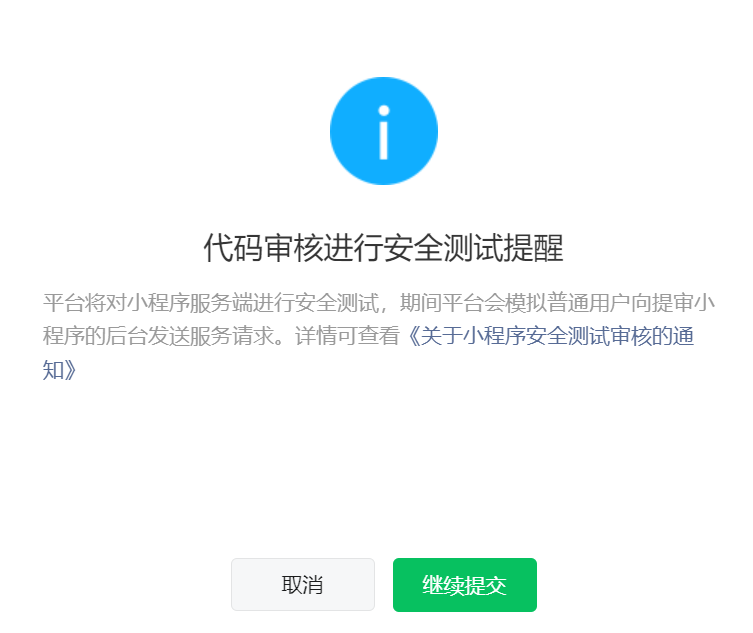
当时的直觉是:服务端是自己写的,不是某个历史漏洞频发的开源系统;数据库只允许本机连接;接口也做了出入参校验,应该不会有太大问题。
测试开始后,后台日志里出现了大量请求,但接口没有明显报错。真正发现异常,是在后台页面查看历史记录时,看到了几十条空白记录。进数据库一看,数据明显不是正常业务流程写进去的。
这类问题有两个判断重点:
- 是否只是写入了垃圾数据。
- 是否存在越权读取、批量删除、数据泄露或权限扩大。
实际现象只观察到异常写入,没有看到敏感数据泄露。但从安全视角看,只要攻击载荷能影响 SQL 语义,就不能按“小脏数据”处理。
从 PM2 日志定位入口
服务是用 PM2 部署的。实时日志可以用:
pm2 logs
但排查历史请求时,更有用的是 PM2 写在磁盘上的日志文件。PM2 默认把日志保存到:
$HOME/.pm2/logs
可以把对应的 out、error 日志拉到本地,再用 rg 搜索关键字。比如:
rg -n -i "union select|sleep\\(|or 1=1|--|/\\*" app-out.log
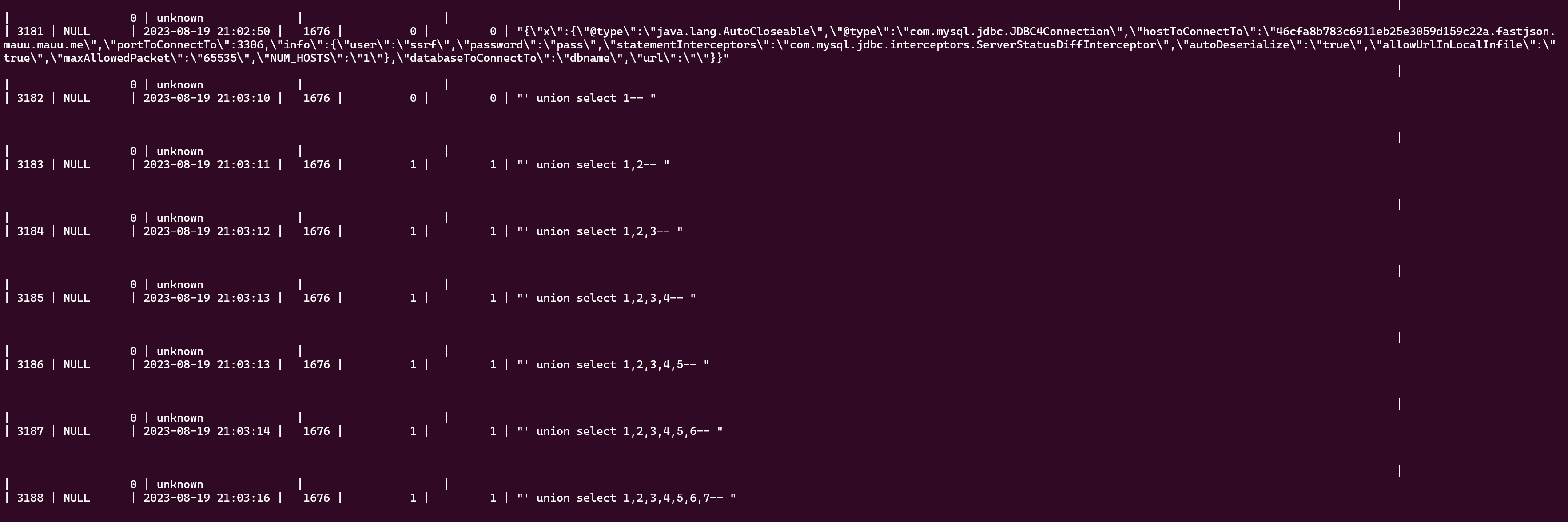
日志里当时能看到类似这样的请求痕迹:
用户 1676 请求历史绘图列表第 1" union select 1,2-- 页
原始日志里还有一些终端颜色控制字符,看起来像乱码:
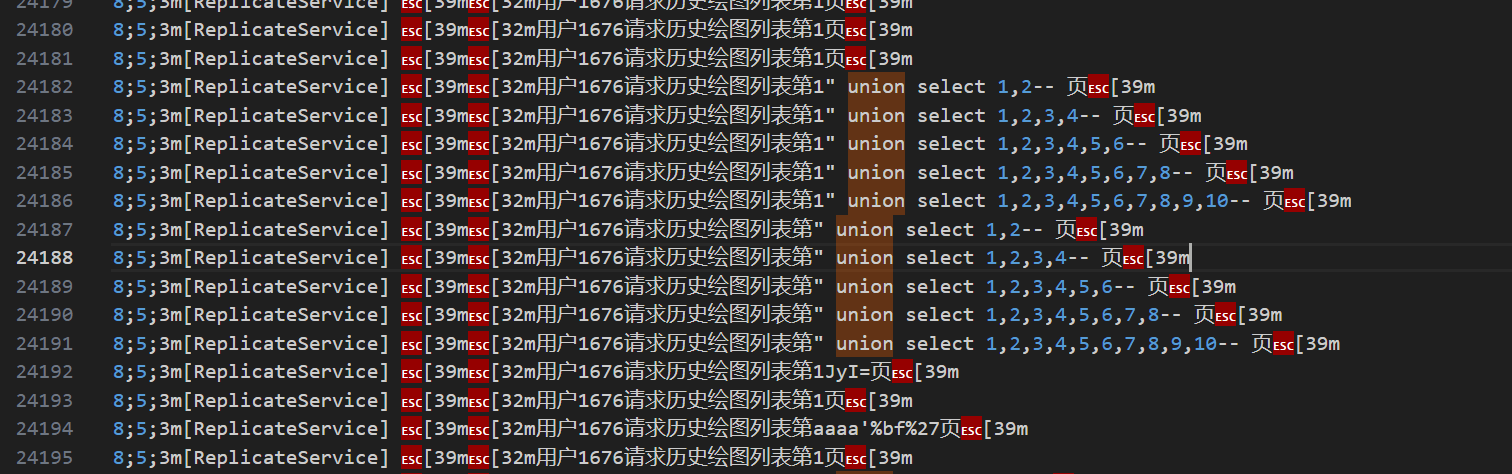
这不是编码问题,而是 ANSI escape code。必要时可以先清理成纯文本再读:
perl -pe 's/\e\[[0-9;]*[mK]//g' app-out.log > app-out.clean.log
从日志看,攻击入口是“历史绘图列表”的分页参数。请求本来应该是第几页,结果页码位置被塞进了 SQL 注入 payload。
根因:把查询参数当成了可信数字
这类分页接口通常长这样:
GET /histories?page=1&pageSize=20
问题出在服务端把 page 当作数字使用,但 HTTP 查询参数进入服务端时天然是字符串。只要没有强制转换和校验,page 就可能是任意字符串。
危险写法通常有两种。
第一种是直接拼 SQL:
const sql = `
SELECT * FROM histories
WHERE user_id = ${userId}
ORDER BY created_at DESC
LIMIT ${(page - 1) * pageSize}, ${pageSize}
`;
第二种是用了 ORM,但某些条件仍然用字符串拼接:
queryBuilder
.where(`history.user_id = ${userId}`)
.take(pageSize)
.skip((page - 1) * pageSize);
这两种都把“不可信输入”放进了 SQL 结构里。只要输入没有被限制为真正的数字,就有被改变 SQL 语义的可能。
修复不能只靠“把已经出现的 payload 过滤掉”。SQL 注入的关键不是某几个危险字符串,而是代码把用户输入当成 SQL 代码的一部分执行了。
OWASP 对 SQL 注入防御的首要建议是参数化查询:SQL 结构先确定,用户输入作为参数绑定进去,让数据库始终能区分代码和数据。输入校验也很重要,但它不是参数化查询的替代品。
NestJS 里应该怎么校验参数
NestJS 提供了 Pipe 和 ValidationPipe,适合把“请求参数必须是什么类型”放在控制器边界上处理。
对简单分页参数,可以直接使用内置 Pipe:
import { DefaultValuePipe, ParseIntPipe, Query } from '@nestjs/common';
@Get('histories')
async listHistories(
@Query('page', new DefaultValuePipe(1), ParseIntPipe) page: number,
@Query('pageSize', new DefaultValuePipe(20), ParseIntPipe) pageSize: number,
) {
const safePage = Math.max(page, 1);
const safePageSize = Math.min(Math.max(pageSize, 1), 50);
return this.historyService.list({
page: safePage,
pageSize: safePageSize,
});
}
如果参数更多,建议用 DTO:
import { Type } from 'class-transformer';
import { IsInt, Max, Min } from 'class-validator';
export class ListHistoryQueryDto {
@Type(() => Number)
@IsInt()
@Min(1)
page = 1;
@Type(() => Number)
@IsInt()
@Min(1)
@Max(50)
pageSize = 20;
}
全局启用 ValidationPipe:
app.useGlobalPipes(
new ValidationPipe({
transform: true,
whitelist: true,
forbidNonWhitelisted: true,
}),
);
几个细节很重要:
transform: true让 DTO 有机会把 query string 转成数字。whitelist: true会移除 DTO 中未声明的字段。forbidNonWhitelisted: true会直接拒绝额外字段,而不是静默吞掉。@Type(() => Number)、@IsInt()、@Min()、@Max()要配合使用,不能只写 TypeScript 的number类型。
TypeScript 类型只存在于编译期,HTTP 请求进来后仍然是字符串。服务端边界必须做运行时校验。
ORM 查询也要避免字符串拼接
使用 ORM 不代表天然免疫 SQL 注入。ORM 的安全性取决于是否使用了它的参数绑定能力。
更稳妥的写法是使用 repository API:
return this.historyRepository.find({
where: {
userId,
},
order: {
createdAt: 'DESC',
},
skip: (page - 1) * pageSize,
take: pageSize,
});
如果必须用 QueryBuilder,条件也要参数化:
return this.historyRepository
.createQueryBuilder('history')
.where('history.user_id = :userId', { userId })
.orderBy('history.created_at', 'DESC')
.skip((page - 1) * pageSize)
.take(pageSize)
.getMany();
不要这样写:
.where(`history.user_id = ${userId}`)
更容易被忽略的是动态排序。字段名、表名、排序方向这类 SQL 结构通常不能用普通参数绑定解决,应该用 allow-list:
const sortFields = {
createdAt: 'history.created_at',
id: 'history.id',
} as const;
const sortDirections = {
asc: 'ASC',
desc: 'DESC',
} as const;
const sortField = sortFields[query.sortBy] ?? sortFields.createdAt;
const sortDirection = sortDirections[query.order] ?? sortDirections.desc;
queryBuilder.orderBy(sortField, sortDirection);
这里不是把用户输入拼进去,而是把用户输入映射到服务端预先定义好的安全选项。
数据库约束是最后一道提醒
后台页面能看到空白记录,说明数据库层也缺少一些约束。
业务上不应该为空的字段,数据库也应该明确表达:
NOT NULL- 合理的
VARCHAR长度 - 枚举或状态字段约束
- 外键或逻辑外键
created_at、updated_at默认值- 必要的唯一索引
数据库约束不能替代服务端校验,也不能防 SQL 注入。但当服务端漏掉某个边界时,数据库约束可以把问题从“悄悄写入脏数据”变成“写入失败并报警”。
对于历史记录这类表,如果业务上必须有用户 ID、图片地址、状态、创建时间,就不应该允许空白行成功入库。
最小权限也不能省
SQL 注入的危害大小,和数据库账号权限直接相关。
个人项目里很容易让应用使用一个权限很大的数据库账号,甚至能建表、删表、改结构。这样省事,但一旦出现注入,破坏半径会变大。
更稳妥的做法是:
- 应用运行账号只拥有业务所需的
SELECT、INSERT、UPDATE、DELETE。 - 迁移账号和运行账号分开,建表改表不使用线上运行账号。
- 不给应用账号
DROP、ALTER、全库管理权限。 - 不同业务库使用不同账号,避免一个服务出问题影响所有数据。
OWASP 也把 least privilege 作为 SQL 注入的纵深防御手段。它不能阻止漏洞出现,但能降低漏洞成功后的损失。
日志应该帮人定位,而不是只堆文本
问题能够定位,是因为日志里记录了关键请求。但原始日志仍然有几个不足:
- 缺少统一 request id。
- 参数、用户、接口路径没有结构化。
- 日志里混有终端颜色控制字符。
- 异常请求没有单独告警。
服务端日志至少应该能回答这些问题:
- 哪个用户或匿名标识发起了请求。
- 请求路径和方法是什么。
- 关键 query/body 参数是什么,敏感字段要脱敏。
- 响应状态码和耗时是多少。
- 异常堆栈和请求上下文如何关联。
结构化日志比彩色文本更适合线上排查。即使不引入复杂日志系统,至少也可以让每条日志是 JSON,后续用 rg、jq、Loki、ELK 等工具都更容易处理。
安全测试不能只靠平台
微信的模拟攻击很有价值,帮助暴露了问题。但平台安全测试只能作为外部信号,不能替代服务端自身的安全工程。
至少应该补几类测试:
it('rejects non-numeric page query', async () => {
await request(app.getHttpServer())
.get('/histories?page=1%22%20union%20select%201,2--')
.expect(400);
});
it('limits pageSize', async () => {
await request(app.getHttpServer())
.get('/histories?page=1&pageSize=10000')
.expect(400);
});
还可以补服务层测试,确保分页参数经过 DTO 或 Pipe 后才进入查询逻辑;再补一条集成测试,确认异常请求不会写入任何业务记录。
安全测试不需要一开始就很复杂。先把已经踩过的坑固化成测试,收益最高。
一份服务端安全复盘清单
类似问题处理后,可以按这张清单检查服务端项目:
- 所有
params、query、body是否都有运行时校验。 - 分页参数是否是整数,并有最小值和最大值。
- 动态排序字段是否使用 allow-list。
- ORM 查询是否使用参数绑定,是否还有 raw SQL 字符串拼接。
- 数据库字段是否有必要的
NOT NULL、长度、索引和状态约束。 - 线上应用数据库账号是否遵循最小权限。
- 错误响应是否避免暴露 SQL、表名、堆栈和服务器路径。
- 日志是否能按 request id 关联用户、接口、参数、状态码和异常。
- 是否有针对已知攻击 payload 的 e2e 测试。
- 是否有异常写入、异常错误率、异常 400/500 的监控。
SQL 注入通常不是孤立问题。它背后往往同时有输入边界不清、查询写法不安全、数据库约束不足、日志不可观测等问题。
总结
这起事故的直接修复,是把分页参数强制转成数字并校验范围。但真正的复盘结论不止这一点。
服务端安全要分层:
- Controller 边界用 Pipe/DTO 做运行时校验。
- 查询层用参数化查询和 ORM 安全 API。
- 动态 SQL 结构用 allow-list。
- 数据库层用约束和最小权限降低损失。
- 日志和测试负责让问题更早被发现、更容易复现。
小程序平台的安全测试只是把问题推到了眼前。真正让系统变安全的,是把问题沉淀成代码约束、数据库约束、测试用例和排查流程。
正在加载讨论...
讨论加载失败。 重新加载